DeepSeek V4 Pro 75% Discount Is Now Permanent. The Frontier Floor Just Moved.
Май 25, 2026 · 6 мин. чтения
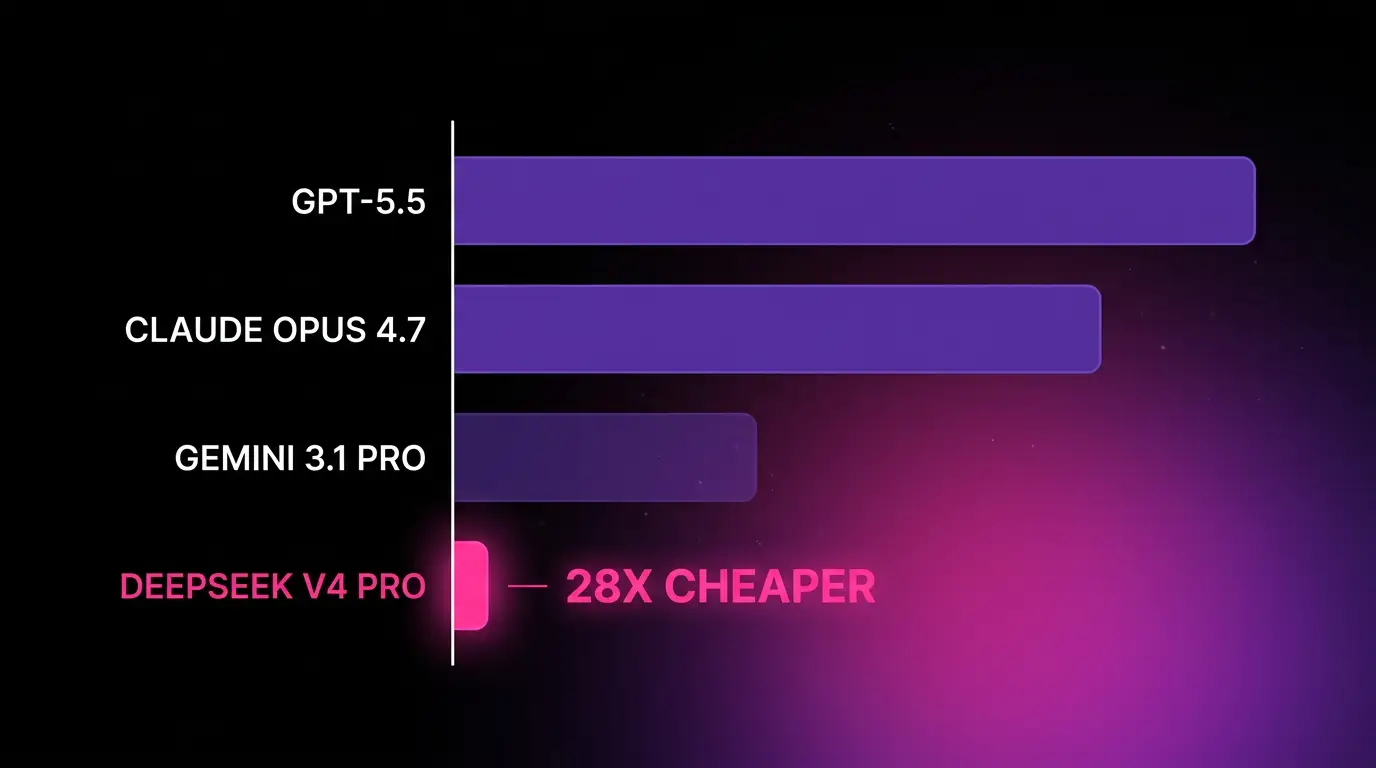
If you’ve been pricing out an agent workload against Claude Opus 4.7 or GPT-5.5, you already know the math. Output tokens at $25 to $30 per million stack up fast. A code review agent, a research loop, a long-context document pipeline. Run any of these at production volume against the US frontier APIs and the cost of the model often exceeds the value of the output. DeepSeek V4 Pro’ s new pricing just got released.
And the math just changed.
Direct answer
DeepSeek announced on May 22, 2026 that the 75% discount on its flagship V4 Pro model is now permanent. New pricing: $0.003625 per million tokens (cache hit), $0.435 (cache miss input), and $0.87 (output). That’s roughly 28x cheaper than Claude Opus 4.7 on output tokens.
What was announced
DeepSeek confirmed on its X account and API docs that the 75% discount on V4 Pro, originally scheduled to expire May 31, 2026, is now the permanent rate. The promotional pricing becomes the official pricing.
New permanent pricing for deepseek-v4-pro:
| Token type | New price (per 1M tokens) | Original price | Discount |
|---|---|---|---|
| Input (cache hit) | $0.003625 | $0.0145 | 75% off |
| Input (cache miss) | $0.435 | $1.74 | 75% off |
| Output | $0.87 | $3.48 | 75% off |
Per DeepSeek’s official notice, the pricing is officially adjusted to 1/4 of the original after the promotional period.
What V4 Pro actually is
DeepSeek V4 Pro launched April 24, 2026 as a 1.6 trillion parameter Mixture of Experts model with 49B active per forward pass. The key specs:
- 1M token context window standard, not a paid add-on.
- Open source under MIT license, weights on Hugging Face.
- Hybrid attention architecture (Compressed Sparse Attention plus Heavily Compressed Attention) that drops single-token inference cost to roughly 27% of V3.2 at 1M context, with the KV cache at about 10%.
- Leads all open-source models on agentic coding benchmarks per DeepSeek’s release notes.
This is not a budget chatbot model. It’s a frontier-tier system that DeepSeek positioned as competitive with closed models from OpenAI, Anthropic, and Google.
How V4 Pro compares at the new price point
Pricing as of May 24, 2026, per provider documentation:
| Model | Input ($/1M) | Output ($/1M) |
|---|---|---|
| Claude Opus 4.7 | $5.00 | $25.00 |
| GPT-5.5 | $5.00 | $30.00 |
| Gemini 3.1 Pro | $2.00 | $12.00 |
| Claude Sonnet 4.6 | $3.00 | $15.00 |
| DeepSeek V4 Pro (new permanent) | $0.435 | $0.87 |
V4 Pro is roughly 11x cheaper than Claude Opus 4.7 on input and 28x cheaper on output. Against GPT-5.5 the output gap is 34x. Even against Gemini 3.1 Pro, the cheapest frontier offering from a US-aligned lab, V4 Pro is more than 13x cheaper on output.
Why the cut is permanent now, not later
DeepSeek originally said V4 Pro pricing would drop later in 2026 once Huawei Ascend 950 chips shipped in volume. Bloomberg and Engadget report the permanent cut arrived months ahead of that target. DeepSeek has not officially confirmed whether expanded Ascend 950 capacity is the reason, but the timing suggests the supply constraint that justified the original premium has eased.
DeepSeek is also reportedly in talks to raise outside funding for the first time, with Tencent and Alibaba among potential investors. Locking in a structurally lower price point is a credible market share play.
What this means for builders
Three concrete shifts.
Agent workloads that weren’t viable on Western frontier APIs are viable on V4 Pro. A long-running code review agent burning through 50M output tokens a month costs $1,500 on Claude Opus 4.7. The same workload runs $43.50 on V4 Pro at the new permanent rate. That gap rewrites the business case for entire categories of agentic applications.
Multi-provider routing is now a cost discipline, not just a reliability story. If you can route the agent loop to V4 Pro, the final review pass to Opus 4.7, and a specific tool-call schema to GPT-5.5, you cut blended cost without losing quality where it matters. Single-provider lock-in is now actively losing you money.
The price floor isn’t going back up. With V4 Pro as a permanent reference price, US labs are under pressure to either match (margin pain), differentiate hard on quality (which Opus 4.7 is doing), or accept losing the cost-sensitive segment.
This is where an API gateway earns its keep. Building against a single provider means rewriting your stack every time pricing or model availability shifts. Building against a gateway means the same OpenAI-compatible code that ran against GPT-5.5 yesterday runs against V4 Pro today, and against whatever shows up at $0.50 next quarter, with no code change.
MixRoute routes every request across 50+ models on price and latency, with automatic failover when a provider degrades. V4 Pro is one of them. Switching the model name in your config is the whole migration:
from openai import OpenAI
client = OpenAI(
base_url="https://api.mixroute.ai/v1",
api_key="YOUR_MIXROUTE_KEY"
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[{"role": "user", "content": "Refactor this function..."}]
)
FAQ
What is DeepSeek V4 Pro? A 1.6 trillion parameter Mixture of Experts model with 49B active per forward pass, 1M token context, and MIT-licensed open weights. Released April 24, 2026.
How much does DeepSeek V4 Pro cost as of May 24, 2026? $0.003625 per million tokens on cache hit input, $0.435 on cache miss input, and $0.87 per million output tokens. These rates are now permanent.
Is DeepSeek V4 Pro cheaper than Claude Opus 4.7 or GPT-5.5? Yes. V4 Pro is roughly 11x cheaper than Opus 4.7 on input and 28x cheaper on output. Against GPT-5.5, the output gap is 34x.
When did the 75% discount become permanent? DeepSeek confirmed the permanent pricing on May 22, 2026. The promotional period was originally set to end May 31, 2026.
Does the discount apply to prompt caching too? Yes. Cache hit input is now $0.003625 per million tokens, down from $0.0145. That’s the cheapest cached input price among frontier-tier models.
How do I switch from Claude or GPT to DeepSeek V4 Pro without rewriting my code? Through an OpenAI-compatible gateway. With MixRoute, you change the model name in your existing OpenAI SDK call. No new SDK, no new auth flow, no separate billing relationship to set up.
Bottom line
The 75% V4 Pro discount being permanent moves the frontier API price floor down by an order of magnitude. The teams that win the next twelve months won’t be the ones loyal to a single provider, they’ll be the ones routing per request to the model that delivers the right quality at the right cost.
MixRoute does exactly that. 50+ models behind one OpenAI-compatible API, automatic failover, USDT deposits with no KYC. Five minutes from signup to first API call against V4 Pro. Start building on MixRoute.